
[ 엘라스틱 서치 바이블 ] 공부한 후 정리한 내용 입니다!!!
1. 엘라스틱 기본 동작
- 키바나 > management > dev tools 로 들어가 편리하게 실습 가능
(1-1) 문서 색인
- 엘라스틱서치 문서 색인 시 ( 색인할 인덱스 이름, _id 값, 문서내용 ) 을 본문에 담아 REST API를 호출
- _id 값은 인덱스 내 고유 식별 값
### 엘라스틱서치 색인 형식
PUT [인덱스 명]/_doc/[_id]
{
[문서 내용]
}
### PUT, POST 차이
PUT : ID값 명시 해줘야됨 ( 같은 id 존재시 덮어쓰기 )
POST : ID값 명시 별도 지정 안함 ( 엘라스틱서치가 자동으로 _id 값 생성 ) - id 지정은 가능..
### 실습 예제 ( PUT )
PUT sy_index/_doc/1
{
"title": "hello world",
"views": 1234,
"public": true,
"created": "2024-11-26"
}
### 실습 예제 ( POST )
POST sy_index/_doc
{
"title": "hello world",
"views": 1234,
"public": true,
"created": "2024-11-26"
}
(1-2) 문서 조회
엘라스틱서치 문서 조회시 인덱스 이름과 _id 값을 지정해 GET 메서드로 호출
### 엘라스틱서치 문서 조회
GET [인덱스 명]/_doc/[_id값]
### 실습 예제 ( GET 조회 )
1) GET sy_index/_doc/1 (키바나 조회)
2) curl -XGET "192.168.219.20:9200/sy_index/_doc/1" -H "Content-Type: application/json" (CLI 조회)
>>> 색인한 문서의 내용 확인 사능
조회 결과 확인

(1-3) 문서 업데이트
- 엘라스틱서치 문서 업데이트 시 ( 인덱스 명, _id ) 값 지정
- 업데이트 api는 _update 사용
- 업데이트할 내용 doc 필드 안에 지정
### 엘라스틱서치 문서 업데이트
POST [인덱스 명]/_update/[_id 값]
{
"doc": {
[문서 내용]
}
}
### 실습 예제 ( _update ), title 필드 업데이트
POST sy_index/_update/1
{
"doc": {
"title": "hello sy0218 elasticsearch!"
}
}
(1-4) 문서 검색
- 엘라스틱서치는 다양한 검색쿼리 가능
- GET 메소드를 사용해 [인덱스 명]/_search를 붙여 본문에는 엘라스틱서치 쿼리를 사용
### 엘라스틱 서치 검색 ( match 쿼리 )
GET sy_index/_search
{
"query": {
"match": {
"title": "hellow world"
}
}
}
검색 결과

- title 필드 지정 검색어 "hello world"로 두 개 문서가 검색
- _score에서 유사도 점수 확인가능 ( 전통적인 RDBMS와 다른 검색 방식 ) - 엘라스틱서치는 전문 검색을 지원하는 검색 엔진
- 단순 주어진 텍스트와 매칭되는 문서를 찾는 것이 아닌 문서를 분석 후 역색인을 만들어 두고 검색어를 분석해 둘 사이 유사도가 높은 문서를 찾는것!!
(1-5) 문서 삭제
엘라스틱서치 문서 삭제 API는 DELETE 메서드를 사용해 [인덱스 명]/_doc/[_id값] 지정
### 엘라스틱서치 문서 삭제
DELETE [인덱스 명]/_doc/[_id값]
### 실습 예제 ( DELETE )
DELETE sy_index/_doc/1
### 삭제 확인
curl -X GET "http://192.168.219.20:9200/sy_index/_search" -H "Content-Type: application/json" -d '{
"_source": false,
"query": {
"match_all": {}
}
}'
2. 엘라스틱 구조

- 문서 : 엘라스틱서치 저장 및 색인을 생성하는 JSON 문서
- 인덱스 : 문서를 모은 단위, 클라이언트는 인덱스 단위로 엘라스틱서치에 검색 요청
- 샤드 : 인덱스는 내용을 샤드로 분리해 분산 저장, 샤드는 복제되어 저장 ( 원본 : 주 샤드, 복제 : 복제본 샤드 )
- _id : 인덱스 내 문서에 부여되는 고유한 구분자 ( 인덱스명, _id 조합은 엘라스틱서치 클러스터내에 고유 )
- 노드 : 엘라스틱서치 프로세스 하나가 노드 하나 구성, 노드는 여러개의 샤드를 가지는데 같은 종류 샤드는 같은 노드에 배치되지 않음 ( 고가용성 위해 )
- 클러스터 : 엘라스틱서치 노드 여러개가 모여 하나의 클러스터 구성
노드의 역할
1) 마스터 노드 : 클러스터 관리의 중요한 역할을 하는 노드
2) 데이터 노드 : 샤드를 보유하고 샤드에 실제 읽기와 쓰기 작업을 수행하는 노드
3) 조정 노드 : 클라이언트 요청을 받아 데이터 노드에 요청을 분배, 클라이언트에 응답을 돌려주는 노드
3. 엘라스틱서치 내부 구조, 루씬
- 엘라스틱서치는 루씬을 코어 라이브러리로 사용
- 루씬 : 문서를 색인하고 검색하는 라이브러리
(3-1) 엘라스틱 동작 개념
- 문서 색인 요청 시 루씬은 문서를 분석 후 역색인 생성
- 루씬 flush : 최초 생성은 메모리 버퍼 >>> 문서 색인, 업데이트, 삭제 작업 수행되면 루씬은 이런 변경을 메모리에 기록하고 주기적으로 디스크에 flush

1) 엘라스틱 색인 요청
- 데이터 메모리 버퍼에 저장, 트랜잭션 로그에 기록
2) 엘라스틱 refresh, 루씬 flush
| 루씬 flush | 엘라스틱 refresh | |
| 역할 | 메모리 데이터를 세그먼트로 디스크에 저장 | 새로 생성된 Lucene 세그먼트를 Elasticsearch 검색에 반영 |
| 검색 가능 | Lucene에서 검색 가능 | Elasticsearch에서 검색 가능 |
| 주기 | 메모리 용량 초과, 명시적 Flush 호출 시 발생 | 기본적으로 1초 간격으로 자동 실행(설정 변경 가능) |
3) 엘라스틱 flush ,루씬 commit
- 루씬 commit 는 주기적으로 fsync를 호출하여 페이지 캐시 내용을 디스크에 강제로 기록 ( 동기화 보장 )
| 엘라스틱서치 flush ( 작업 요약 ) | |
| Lucene flush | 메모리 데이터를 세그먼트 파일로 저장 (검색 가능 상태로 만듦). |
| Lucene commit | 세그먼트 파일과 메타데이터를 영구 저장 및 fsync로 디스크에 동기화. |
| Translog 초기화 | Lucene 세그먼트에 반영된 데이터를 기반으로 Translog를 초기화하고 새로운 Translog 파일 생성. |
(3-2) 세그먼트
- 위의 작업을 거쳐 디스크에 기록된 파일들이 모이면 세그먼트 단위가 됨
- 세그먼트는 루씬의 검색 대상
- 세그먼트는 불변 데이터 ( 새로운 문서는 새로운 세그먼트 생성, 기존 문서 삭제 시 삭제 플래그만 표시 )
- 불변인 세그먼트 개수를 무작정 늘려갈 수 없기에 루씬은 중간중간 세그먼트 병합 수행
- 세그먼트 병합 : 삭제 플래그 표시된 데이터를 삭제
- 세그먼트 병합은 오버헤드가 많지만 수행하면 검색 성능 향상 가능
세그먼트 병합은 더 이상 추가 데이터 색인이 없을 것이 보장될 떄 수행!!!!!!!
추가된 세그먼트는 병합 대상 선정에서 영원히 누락될 수 있음... ㅠㅠ
(3-3) 루씬 인덱스, 엘라스틱서치 인덱스
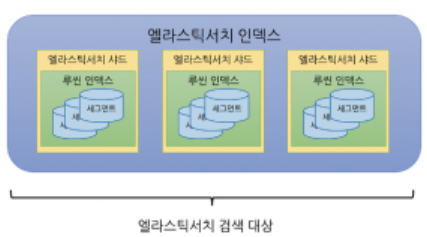
- 루씬 인덱스 >>> 엘라스틱서치 샤드 >>> 엘라스틱서치 인덱스
- 새 문서 색인시 해당 내용을 라우팅해 여러 샤드에 분산시켜 저장, 색인
- 엘라스틱서치 검색 요청 : 각 샤드를 대상으로 검색 후 결과를 모아 병합해 최종 응답
- 샤드는 여러 노드에 분산 저장, 노드가 모여 엘라스틱서치 클러스터가 됨
(3-4) translog ( 트랜잭션 로그 )
- 장애 발생시 데이터 유실을 해결하기 위해 엘라스틱서치 샤드는 모든 작업마다 translog 라는 작업 로그를 남김
- translog는 ( 색인, 삭제 ) 작업이 루씬 인덱스에 수행된 직후 기록, translog 기록까지 끝난 이후 작업 요청 성공 승인
- es 장애 발생시 >> 샤드 복구 단계서 translog를 읽음 >> translog 기록은 했지만 루씬 commit에 포함되지 못한 작업 내용을 복구
- translog 크기가 커지면 복구에 오랜 시간이 걸림, 이를 위해 엘라스틱서치 flush로 루씬 commit를 수행하고 새로운 translog를 만드는 작업을 진행 ( translog를 적절한 수준으로 유지 )

'데이터 엔지니어( 실습 정리 ) > elasticsearch' 카테고리의 다른 글
| 4. 데이터 다루기 (3, 4, 5) (1) | 2024.12.19 |
|---|---|
| 4. 데이터 다루기 (1, 2) (0) | 2024.12.14 |
| 3. 엘라스틱서치 인덱스 설계 (3, 4, 5) (0) | 2024.12.10 |
| 3. 엘라스틱서치 인덱스 설계 (1, 2) (0) | 2024.12.01 |
| 1. 엘라스틱서치 소개 및 설치 (0) | 2024.11.18 |



