자자 오늘은 csv파일을 몽고db에 저장하는 실습을 수행해보자!!!
1. 일단은 pymongo 모듈을 설치해주자!!
pip install pymongo
2. 스파크에서 MongoDB에 저장할 때는 추가적인 라이브러리가 필요합니다. 최신 버전의 스파크에서는 spark-mongodb 라이브러리를 사용하여 MongoDB에 데이터를 저장할 수 있다!!!
1) --packages 옵션을 사용하여 Maven 중앙 저장소에서 MongoDB Spark Connector를 다운로드하고 관리하도록 설정
spark-submit --master yarn --deploy-mode client --packages org.mongodb.spark:mongo-spark-connector_2.12:3.0.0 test.py
mongo_test.py >>> 간단 실험용 예제
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql.functions import col
import pymongo
# Spark 세션 생성
spark = SparkSession.builder \
.appName("MongoDBExample") \
.getOrCreate()
# 예제 데이터 생성
data = [Row(id=1, name="Alice", age=28),
Row(id=2, name="Bob", age=35),
Row(id=3, name="Charlie", age=22)]
# 데이터프레임 생성
df = spark.createDataFrame(data)
# MongoDB에 연결
client = pymongo.MongoClient("mongodb://172.31.8.150:27017/")
db = client["test"]
collection = db["test_data"]
# 데이터프레임을 MongoDB에 저장
df.write.format("mongo").mode("overwrite").option("uri", "mongodb://172.31.8.150:27017/test.test_data").save()
# 저장된 데이터 조회
mongo_data = list(collection.find({}))
for doc in mongo_data:
print(doc)
# Spark 세션 종료
spark.stop()spark-submit --master yarn --deploy-mode client --packages org.mongodb.spark:mongo-spark-connector_2.12:3.0.0 mongo_test.py
오류발생 ...
몽고db에 연결되지 않는 오류...
그래서 인스턴스에서 로컬로(몽고db설치됨) ping을 보내보았지만 통하지 않음... 무슨 문제일까
다음에 해결하기로하고
aws에서 db인스턴스 하나올려서 거기 몽고db설치해서 실습해보자
1. apt저장소 추가
wget -qO - https://www.mongodb.org/static/pgp/server-5.0.asc | sudo apt-key add -
2. apt저장소 등록
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu $(lsb_release -cs)/mongodb-org/5.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-5.0.list
3. 패키지 목록 업데이트
sudo apt update
4. 몽고db 설치
sudo apt install -y mongodb-org
5. 몽고db 서비스 시작
sudo systemctl start mongod
6. 부팅 시 자동 시작 설정
sudo systemctl enable mongod
7. 몽고db 접속
쉘에 >>> mongo
8. 데이터베이스 생성
use coin
9. 컬렉션 생성
db.createCollection("coin_data")
10. db, 컬렉션 생성 확인 명령어
show dbs, show collections몽고db 외부에서 접속 허용하기
1. mongod.conf 파일 편집: MongoDB 구성 파일(mongod.conf)을 열어서 bindIp 설정을 변경합니다.
sudo nano /etc/mongod.conf
2.bindIp 설정 변경: bindIp 설정을 원하는 값으로 변경합니다. 예를 들어, 모든 IP 주소로부터의 연결을 허용하려면 다음과 같이 설정
bindIp: 0.0.0.0
3. MongoDB 재시작: 설정을 변경한 후에는 MongoDB 서비스를 재시작
sudo service mongod restart
특정 IP 주소 허용: 몽고DB의 포트(기본적으로 27017)를 특정 IP 주소에서만 접근 가능하도록 방화벽 설정을 변경
sudo apt-get update
sudo apt-get install ufw
sudo ufw enable
특정 IP 주소 허용: sudo ufw allow from <특정 IP 주소> to any port 27017
특정 IP 주소 허용: 몽고DB의 포트(기본적으로 27017)를 특정 IP 주소에서만 접근 가능하도록 방화벽 설정을 변경
sudo ufw status >>> 설정확인

spark-submit --master yarn --deploy-mode client --packages org.mongodb.spark:mongo-spark-connector_2.12:3.0.0 mongo_test.py >>> 명령어를 사용하여 mongo_test.py 실행

어??? 이게 되네 일단은 늦었으니까 나머지는 내일한번 해결해보는걸로 해보자!!!!
mongo.py >> 실제 csv넣는 코드
from pyspark.sql import SparkSession
import pymongo
# 스파크 세션 생성
spark = SparkSession.builder \
.master("yarn") \
.appName("CSV to MongoDB") \
.getOrCreate()
# HDFS에서 CSV 파일 읽어오기
csv_path = "hdfs:///user/ubuntu/coin_data.csv/*.csv"
csv_df = spark.read.option("header", "true").csv(csv_path)
# MongoDB에 연결
client = pymongo.MongoClient("mongodb://172.31.7.134:27017/")
db = client["coin"]
collection = db["coin_data"]
# 데이터프레임을 MongoDB에 저장
csv_df.write.format("mongo").mode("overwrite").option("uri", "mongodb://172.31.7.134:27017/coin.coin_data").save()
print("성공")
# 스파크 세션 종료
spark.stop()spark-submit --master yarn --deploy-mode client --packages org.mongodb.spark:mongo-spark-connector_2.12:3.0.0 mongo.py >>> 실행
use coin
db.coin_data.find() >>> coin_data 컬렉션 모든 데이터 확인하는 코드
데이터가 저장되었는지 확인해보자!!
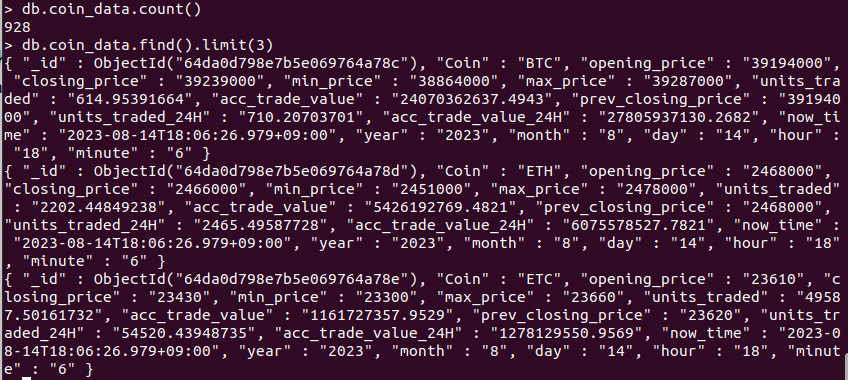
Apache Airflow를 사용하여 매시간 10분마다 스파크 애플리케이션을 실행하는 작업을 예약
- 아파치 에어플로우는 워크플로우 자동화 및 스케줄링 도구
1. airflow를 설치후 실행, 이후 웹ui에 접속해 작업을 정의
(1) pip install apache-airflow >>> airflow 설치
(2) echo 'export PATH="$PATH:$HOME/.local/bin"' >> ~/.bashrc : airflow 명령이 설치된 경로가 PATH 환경 변수에 추가,
추가하지 않으면 나중에 airflow 명령을 사용할때 경로를 입력해야하는 불편함 초래...
source ~/.bashrc >> 변경사항 적용
(3) airflow db init : airflow 초기화
(4) cd airflow >>> vim airflow.cfg

9898포트로 변경해주자
timezone두 서울로 바꿔주자

false로 수정
rm -rf ./airflow.db
airflow db init
(5) airflow users create --username wntpdyd0218 --firstname syoung --lastname ju --role Admin --email sy02229@gmail.com --password 1234
사용자 이름 : wntpdyd0218
비밀번호 : 1234
(6) airflow webserver -D >>> 에어플로우 웹서버 백그라운드 실행후http://13.124.183.182:9898/ >>> 접속
2. airflow 웹 ui에 접속후 DAGs 메뉴로 이동해 새로운 DAG 작업 생성
3. DAG 정의 파일을 작성
cd airflow >>> mkdir dags >>> cd dags
dags디렉토리 안에 만들어야됨!!
from airflow.operators.bash_operator import BashOperator
from airflow import DAG
from datetime import datetime, timedelta
import pytz
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 8, 17, tzinfo=pytz.timezone('Asia/Seoul')),
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'spark_submit_new_dag',
default_args=default_args,
schedule_interval='10 * * * *', # 매시간 10분마다 실행
catchup=False, # 과거 작업은 실행하지 않음
)
# coin_union_csv.py 실행
spark_submit_task = BashOperator(
task_id='airflow_load_csv',
bash_command='/usr/local/spark/bin/spark-submit --master yarn --deploy-mode client /home/ubuntu/coinfull_union_csv.py',
dag=dag,
)
# fullcoin_push_mongo.py 실행
push_mongo_task = BashOperator(
task_id='airflow_push_mongo',
bash_command='/usr/local/spark/bin/spark-submit --master yarn --deploy-mode client --packages org.mongodb.spark:mongo-spark-connector_2.12:3.0.0 /home/ubuntu/mongo.py', # 파이썬 >실행
dag=dag,
)
# Task 간 의존성 설정
spark_submit_task >> push_mongo_task
스파크 실행 경로 확인 하는 방법
1. 환경변수 환인 : echo $SPARK_HOME
2. which 명령어 사용( 스파크 실행 파일의 실제 경로를 찾을 수도 있다 ) : spark-submit

ex) DAG파일예
spark_submit_task = BashOperator(
task_id='spark_submit_task',
bash_command='/usr/local/spark/bin/spark-submit --master yarn --deploy-mode client --packages org.mongodb.spark:mongo-spark-connector_2.12:3.0.0 mongu.py',
dag=dag,
)chmod +x coinfull_union_csv.py : 10분마다 실행해야되기에 실행권한 주기
chmod +x mongo.py : 10분마다 실행해야되기에 실행권한 주기
airflow scheduler -D : scheduler 백그라운드 실행하기
최종 dag파일
from airflow.operators.bash_operator import BashOperator
from airflow import DAG
from datetime import datetime, timedelta
import pytz
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 8, 17, tzinfo=pytz.timezone('Asia/Seoul')),
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'spark_submit_new_dag',
default_args=default_args,
schedule_interval='10 * * * *', # 매시간 10분마다 실행
catchup=False, # 과거 작업은 실행하지 않음
)
# coin_union_csv.py 실행
spark_submit_task = BashOperator(
task_id='airflow_load_csv',
bash_command='/usr/local/spark/bin/spark-submit --master yarn --deploy-mode client /home/ubuntu/coinfull_union_csv.py',
dag=dag,
)
# fullcoin_push_mongo.py 실행
push_mongo_task = BashOperator(
task_id='airflow_push_mongo',
bash_command='/usr/local/spark/bin/spark-submit --master yarn --deploy-mode client --packages org.mongodb.spark:mongo-spark-connector_2.12:3.0.0 /home/ubuntu/mongo.py', # 파이썬 >실행
dag=dag,
)
# Task 간 의존성 설정
spark_submit_task >> push_mongo_task
백그라운드 실행중인 데몬 종료시키는법
ps aux | grep airflow >>> airflow와 관련 실행중인 프로세스 확인
kill <PID> : pid를 사용한 데몬 종료
ex )))
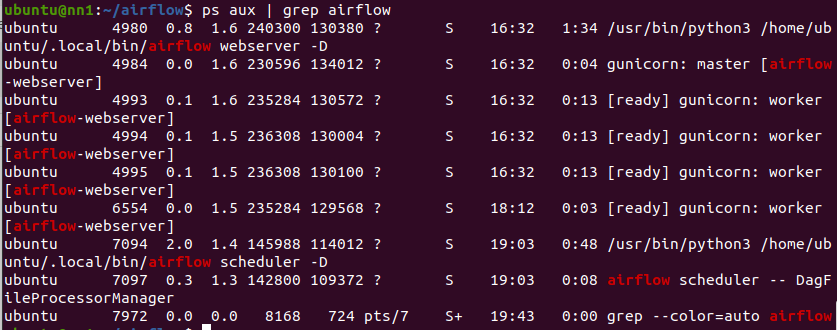
만약 scheduler 벡그라운드 프로세스를 종료시키려면
kill 7094

사라진것을 확인!!
kill하고 airflow scheduler -D 다시 실행 ㄱㄱㄱ
그리고 airflow 웹사이트에 들어가면

실행시켜주자
완료후 몽고 db에 데이터가 들어갔는지 확인!!!!

오 들어갔음!!!!!

자자 이제 주피터에서 몽고db데이터를 가져와보자!!!
1. 일단 보안규칙 추가해주자 : 사용자지정tcp, 27017, 모든 ip(편의상)
2. 주피터 노트북 시작
!pip install pymongo
------------------------------------------------------------------------------
from pymongo import MongoClient
# MongoDB 연결 설정
client = MongoClient("mongodb://43.202.67.139:27017/")
db = client["coin"] # 데이터베이스명
try:
# 연결 확인
client.server_info()
print("MongoDB 연결 성공")
except Exception as e:
print("MongoDB 연결 실패:", e)
연결 성공!!!!
3. 이제 데이터를 가져와보기
from pymongo import MongoClient
# MongoDB 연결 설정
client = MongoClient("mongodb://43.202.67.139:27017/")
db = client["coin"] # 데이터베이스명
collection = db["coin_data"] # 컬렉션명
# 컬렉션 데이터 조회
data = collection.find()
# 조회된 데이터 출력
for doc in data:
print(doc)
와우

4. 가져온 데이터를 데이터 프레임으로 바꿔주자!!!
import pandas as pd
from pymongo import MongoClient
# MongoDB 연결 설정
client = MongoClient("mongodb://43.202.67.139:27017/")
db = client["coin"] # 데이터베이스명
collection = db["coin_data"] # 컬렉션명
# 컬렉션 데이터 조회
data = collection.find()
# 데이터프레임으로 변환
df = pd.DataFrame(data)
# _id 컬럼은 제거해주자
df = df.drop(columns="_id")
# 출력
print(len(df))
df.head()
#df.loc[df['Coin'] == 'BTC']출력 확인!!

'데이터 엔지니어( 실습 정리 )' 카테고리의 다른 글
| 카프카, 스파크 스트리밍 던파 데이터 수집 실습(0) (1) | 2023.10.06 |
|---|---|
| 카프카 aws인프라(1) (0) | 2023.09.30 |
| 하둡, 스파크 코인 데이터 수집하기(0) (0) | 2023.08.10 |
| 하둡, 스파크 코인 데이터 수집하기(1) (0) | 2023.08.09 |
| (1일차-1)java, 하둡 설치 (0) | 2023.08.02 |


