일단 인스턴스 하나 생성해주기
우분투, 인스턴스유형 t2라지, 보안그룹 생성 ssh 내ip, 스토리지20gib
1. ssh 설정
mkdir -p ~/identity
mv ~/Downloads/hadoop_eco_system.pem ~/identity/hadoop_eco_system.pem
# pem 키 권한 변경 -> 600이 아닐 경우 보안 취약으로 판단
chmod 600 ~/identity/hadoop_eco_system.pem
# ssh key 만들기
ssh-keygen -t rsa
# config 파일 설정
vim ~/.ssh/config
Host nn1
HostName 43.201.49.44
User ubuntu
IdentityFile ~/identity/hadoop_eco_system.pemchmod 440 ~/.ssh/config
ssh nn1 >>> 접속 되는지 확인
1. aws 하둡,스파크 빅데이터 환경 구축
(1) 필요 라이브러리 설치
sudo apt-get -y update
sudo apt-get -y upgrade
sudo apt-get -y dist-upgrade
sudo apt-get install -y vim wget unzip ssh openssh-* net-tools(2) 자바 설치
sudo apt-get install -y openjdk-8-jdkjava -version >>> 자바 버전 확인
sudo find / -name java-8-openjdk-amd64 2>/dev/null >>> 환경변수에 추가해줄 경로를 확인

(3) 하둡 설치
1. 하둡 설치
sudo wget https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
2. 압축 해제
sudo tar -zxvf hadoop-3.2.3.tar.gz -C /usr/local
3. 이름 변경(좀더 쉽게쉽게 하기위해)
sudo mv /usr/local/hadoop-3.2.3 /usr/local/hadoop
1. hdfs-site.xml 편집 [ Hadoop 클러스터의 구성을 정의하고 구성 요소 간의 상호 작용 방식을 결정하는 데 사용 ]
sudo vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<!-- configuration hadoop -->
<property>
# 파일 복제 수를 지정
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
# NameNode의 메타데이터를 저장할 디렉토리 경로
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/nameNode</value>
</property>
<property>
# DataNode의 데이터 블록을 저장할 디렉토리 경로
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/dataNode</value>
</property>
<property>
# JournalNode의 트랜잭션 로그 파일을 저장할 디렉토리 경로
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/data/dfs/journalnode</value>
</property>
<property>
# HDFS 네임서비스의 이름
<name>dfs.nameservices</name>
<value>my-hadoop-cluster</value>
</property>
<property>
# 네임노드의 하이언 노드 이름 목록을 지정
<name>dfs.ha.namenodes.my-hadoop-cluster</name>
<value>namenode1,namenode2</value>
</property>
<property>
# 네임노드의 RPC 주소를 지정
<name>dfs.namenode.rpc-address.my-hadoop-cluster.namenode1</name>
<value>nn1:8020</value>
</property>
<property>
# 네임노드의 RPC 주소를 지정
<name>dfs.namenode.rpc-address.my-hadoop-cluster.namenode2</name>
<value>nn2:8020</value>
</property>
<property>
# 네임노드의 HTTP 주소를 지정
<name>dfs.namenode.http-address.my-hadoop-cluster.namenode1</name>
<value>nn1:50070</value>
</property>
<property>
# 네임노드의 HTTP 주소를 지정
<name>dfs.namenode.http-address.my-hadoop-cluster.namenode2</name>
<value>nn2:50070</value>
</property>
<property>
# 네임노드 간의 공유 트랜잭션 로그 디렉토리를 지정
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://nn1:8485;nn2:8485;dn1:8485/my-hadoop-cluster</value>
</property>
<property>
# 클라이언트 장애 조치(Failover) 프록시 제공자를 지정
<name>dfs.client.failover.proxy.provider.my-hadoop-cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
# 네임노드 장애 조치 시 사용되는 팬싱(fencing) 메서드를 지정
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
# SSH 팬싱을 위한 개인 키 파일의 경로를 지정
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/ubuntu/.ssh/id_rsa</value>
</property>
<property>
# 자동 장애 조치(Failover)를 활성화
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
# HDFS 네임노드의 데이터 디렉토리 경로
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/data/name</value>
</property>
<property>
# HDFS 데이터 노드의 데이터 디렉토리 경로
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/data/data</value>
</property>
</configuration>
2. core-site.xml 파일 편집 [ Hadoop 클라이언트가 HDFS에 접근하고 파일 시스템을 사용하는 방식을 지정하는 데 사용 ]
sudo vim $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
# HDFS의 기본 파일 시스템 이름을 지정합니다. 여기서는
# hdfs://nn1:9000으로 설정되어 있으므로
# 클라이언트가 HDFS에 액세스할 때
# 기본적으로 nn1 노드의 9000번 포트를 사용
<name>fs.default.name</name>
<value>hdfs://nn1:9000</value>
</property>
<property>
# HDFS 네임스페이스 my-hadoop-cluster를 기본 파일 시스템으로 사용하도록 설정
<name>fs.defaultFS</name>
<value>hdfs://my-hadoop-cluster</value>
</property>
<property>
# Hadoop 클러스터의 고가용성 (HA) 구성을 위해 사용되는 ZooKeeper 서버의 주소를 지정
<name>ha.zookeeper.quorum</name>
<value>nn1:2181,nn2:2181,dn1:2181</value>
</property>
</configuration>
3. yarn-site.xml 파일 편집 [ YARN 클러스터의 노드 매니저와 리소스 매니저 동작에 영향을 미치는 중요한 속성들을 포함 ]
sudo vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
# MapReduce 작업 실행을 위해 필요한 보조 서비스인 mapreduce_shuffle를 사용하도록 설정
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
# MapReduce 작업의 데이터 셔플링을 처리하는
# org.apache.hadoop.mapred.ShuffleHandler 클래스를 사용하도록 설정
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
# 리소스 매니저의 호스트 이름을 지정
<name>yarn.resourcemanager.hostname</name>
<value>nn1</value>
</property>
<property>
# 노드 매니저의 가상 메모리 (VMem) 검사 기능을 활성화 또는 비활성화
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>51200</value> <!-- 50GB, 또는 사용 가능한 전체 메모리 양 -->
</property>
</configuration>
4. mapred-site.xml 파일 편집 [ MapReduce 작업을 실행할 때 필요한 환경 변수와 설정 ]
sudo vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
# MapReduce 프레임워크를 지정
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
# YARN ApplicationMaster 환경에서 사용할 환경 변수를 설정
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
# Map 작업 환경에서 사용할 환경 변수를 설정
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
# Reduce 작업 환경에서 사용할 환경 변수를 설정
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
5. hadoop-env.sh 파일 편집 [ Hadoop 실행 환경을 구성하는 데 사용되는 스크립트 ]
sudo vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
6. Hadoop workers 편집 [ worker로 동작할 서버 호스트 이름을 설정 ]
sudo vim $HADOOP_HOME/etc/hadoop/workers
dn1
dn2
dn3
7. Hadoop masters 편집 [ master로 동작할 서버 호스트 이름을 설정 ]
sudo vim $HADOOP_HOME/etc/hadoop/masters
nn1
nn2
(4) 스파크 설치
1.스파크 설치
sudo wget https://dlcdn.apache.org/spark/spark-3.2.4/spark-3.2.4-bin-hadoop3.2.tgz
2. 압축 해제
sudo tar -xzvf spark-3.2.4-bin-hadoop3.2.tgz -C /usr/local
3. 이름 변경
sudo mv /usr/local/spark-3.2.4-bin-hadoop3.2 /usr/local/spark
1. spark-env.sh 파일 편집 [ Spark 및 Hadoop을 실행 및 구성하는 데 사용될 환경 변수 ]
cd $SPARK_HOME/conf
sudo cp spark-env.sh.template spark-env.sh
sudo vim spark-env.sh
export SPARK_HOME=/usr/local/spark
export SPARK_CONF_DIR=/usr/local/spark/conf
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_WEBUI_PORT=18080
2. spark-defaults.conf 파일 편집 [ Spark의 클러스터 매니저 정보와 스파크 이벤트 로그에 관한 내용 ]
sudo cp /usr/local/spark/conf/spark-defaults.conf.template /usr/local/spark/conf/spark-defaults.conf
sudo vim /usr/local/spark/conf/spark-defaults.conf
# 클러스터 매니저 정보
spark.master yarn
# 스파크 이벤트 로그 수행 유무
spark.eventLog.enabled true
# 스파크 이벤트 로그 저장 경로
spark.eventLog.dir /usr/local/spark/logs
# 초기 자원 설정
spark.yarn.am.memory 200m
spark.yarn.am.cores 1sudo mkdir -p /usr/local/spark/logs && sudo chown -R $USER:$USER /usr/local/spark/ >>> 스파크 이벤트 로그를 저장할 디렉토리를 생성, 해당 디렉토리의 소유자 및 그룹을 현재 사용자로 변경
3. workers 파일 편집 [ hdfs의 워커를 설정했던것과 같이 스파크도 설정 ]
sudo cp /usr/local/spark/conf/workers.template /usr/local/spark/conf/workers
sudo vim /usr/local/spark/conf/workers
dn1
dn2
dn3(5) 파이썬, 파이스파크 설치
1. Python
sudo apt-get install -y python3-pip
2. PySpark
sudo pip3 install pyspark findspark
(6) 주키퍼 설치
1. 주키퍼 설치
sudo wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.2/apache-zookeeper-3.8.2-bin.tar.gz
2. 압축 해제
sudo tar -xzvf apache-zookeeper-3.8.2-bin.tar.gz -C /usr/local
3. 이름 변경
sudo mv /usr/local/apache-zookeeper-3.8.2-bin /usr/local/zookeeper
1. zoo.cfg 파일 편집 [ ZooKeeper 서버의 설정 정보를 포함 ]
cd /usr/local/zookeeper
sudo cp ./conf/zoo_sample.cfg ./conf/zoo.cfg
sudo vim ./conf/zoo.cfg
# ZooKeeper의 기본 시간 단위인 틱(tick)의 시간 간격을 지정 (2초를 의미)
tickTime=2000
# ZooKeeper 앙상블의 초기 동기화 시간 제한을 지정
initLimit=10
# ZooKeeper 앙상블의 동기화 시간 제한을 지정
syncLimit=5
# ZooKeeper의 데이터 디렉토리를 지정
dataDir=/usr/local/zookeeper/data
# ZooKeeper의 데이터 로그 디렉토리를 지정
dataLogDir=/usr/local/zookeeper/logs
# 클라이언트가 ZooKeeper 서비스에 접속할 때 사용할 포트 번호를 지정
clientPort=2181
# 클라이언트의 최대 연결 수를 지정(0은 제한 없음)
maxClientCnxns=0
# 클라이언트 세션의 최대 제한 시간을 지정
maxSessionTimeout=180000
# ZooKeeper 앙상블의 서버 정보를 지정
server.1=nn1:2888:3888
server.2=nn2:2888:3888
server.3=dn1:2888:3888데이터 디렉토리, 로그 디렉토리 생성
sudo mkdir -p /usr/local/zookeeper/data
sudo mkdir -p /usr/local/zookeeper/logs
2. myid 설정
# 사용자 그룹 변경
sudo chown -R $USER:$USER /usr/local/zookeeper
sudo vim /usr/local/zookeeper/data/myid
1
(7) ssh 설정
ssh-keygen -t rsa
# authorized_keys 생성
cat >> ~/.ssh/authorized_keys < ~/.ssh/id_rsa.pub
# 로컬 접속 확인
ssh localhost
(8) 환경변수, 사용자 환경변수
환경변수
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/usr/lib/jvm/java-8-openjdk-amd64/bin:/usr/local/hadoop/bin:/usr/local/hadoop/sbin:/usr/local/spark/bin:/usr/local/spark/sbin:/usr/bin/python3"
JAVA_HOME="/usr/lib/jvm/java-8-openjdk-amd64"
HADOOP_HOME="/usr/local/hadoop"
SPARK_HOME="/usr/local/spark"
ZOOKEEPER_HOME="/usr/local/zookeeper"변경된 환경변수 적용 >>> source /etc/environment
사용자 환경변수
sudo echo 'export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64' >> ~/.bashrc
sudo echo 'export HADOOP_HOME=/usr/local/hadoop' >> ~/.bashrc
sudo echo 'export HADOOP_COMMON_HOME=$HADOOP_HOME' >> ~/.bashrc
sudo echo 'export HADOOP_HDFS_HOME=$HADOOP_HOME' >> ~/.bashrc
sudo echo 'export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop' >> ~/.bashrc
sudo echo 'export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop' >> ~/.bashrc
sudo echo 'export HADOOP_YARN_HOME=$HADOOP_HOME' >> ~/.bashrc
sudo echo 'export HADOOP_MAPRED_HOME=$HADOOP_HOME' >> ~/.bashrc
sudo echo 'export PYTHONPATH=/usr/bin/python3' >> ~/.bashrc
sudo echo 'export PYSPARK_PYTHON=/usr/bin/python3' >> ~/.bashrc
echo 'export ZOOKEEPER_HOME=/usr/local/zookeeper' >> ~/.bashrc변경된 사용자 환경변수 적용 >>> source ~/.bashrc
(9) 여태까지 만든거 aws에서 ami로 만든후 인스턴스 복제 ㄱㄱ

만들어 지는데 시간좀 걸림...

인스턴스 4개 복제후
1. nn2, dn1, dn2, dn3로 이름변경
2. 인스턴스간 통신을위해 보안그룹 모든트랙픽 , 규칙은 hadoop보안그룹으로 설정
(10) 편한 접속을 위해 로컬에서 ssh설정하기
1. SSH Config 설정
vim ~/.ssh/config
Host nn1
HostName 43.201.49.44
User ubuntu
IdentityFile ~/identity/hadoop_eco_system.pem
Host nn2
HostName 13.125.215.108
User ubuntu
IdentityFile ~/identity/hadoop_eco_system.pem
Host dn1
HostName 52.78.156.129
User ubuntu
IdentityFile ~/identity/hadoop_eco_system.pem
Host dn2
HostName 52.79.94.36
User ubuntu
IdentityFile ~/identity/hadoop_eco_system.pem
Host dn3
HostName 43.202.0.74
User ubuntu
IdentityFile ~/identity/hadoop_eco_system.pemssh nn1 >>> exit >>> ssh nn2 >>>> exit >>> ssh dn1 >>>>>>>>>>
테스트 해보자
(11) hosts, hostname 설정
ssh nn1
sudo vim /etc/hosts
127.0.0.1 localhost
172.31.0.107 nn1
172.31.3.174 nn2
172.31.15.160 dn1
172.31.13.235 dn2
172.31.1.97 dn3
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
ff02::3 ip6-allhosts
~
모든 서버 호스트 이름 설정 ㄱㄱ
ex ) sudo hostnamectl set-hostname nn1
모든 인스턴스에 hosts파일 복제
cat /etc/hosts | ssh nn2 "sudo sh -c 'cat >/etc/hosts'"
cat /etc/hosts | ssh dn1 "sudo sh -c 'cat >/etc/hosts'"
cat /etc/hosts | ssh dn2 "sudo sh -c 'cat >/etc/hosts'"
cat /etc/hosts | ssh dn3 "sudo sh -c 'cat >/etc/hosts'"
hdfs-site.xml 파일 복제
# nn1에서
cat $HADOOP_HOME/etc/hadoop/hdfs-site.xml | ssh nn2 "sudo sh -c 'cat >$HADOOP_HOME/etc/hadoop/hdfs-site.xml'"
(12) 주키퍼 클러스터 설정
1. nn1, nn2, dn1 서버에서 myid를 각각 1, 2, 3으로 편집
ssh nn2 >>> sudo vim /usr/local/zookeeper/data/myid >>> 2
ssh dn1 >>> sudo vim /usr/local/zookeeper/data/myid >>> 3
2. 주키퍼 실행 (nn1, nn2, dn1)
주키퍼는 분산 환경에서 데이터 관리와 동기화를 위한 서비스를 제공하여 여러 서버 또는 프로세스 간의 협력과 조정을 가능
sudo /usr/local/zookeeper/bin/zkServer.sh start >>> 주키퍼 시작
sudo /usr/local/zookeeper/bin/zkServer.sh status >>> 주키퍼 상태 확인

3. hdfs zkfc 초기화
hdfs zkfc -formatZK >>> Hadoop의 HDFS(Hadoop Distributed File System)에서 주키퍼(ZooKeeper)의 포맷을 초기화하는 명령
4. Journalnode 실행 ( nn1, nn2, dn1 에서 실행한다. )
hdfs --daemon start journalnode
jps명령어로 확인해보기 >>> 현재 실행 중인 JVM 프로세스와 각 프로세스의 이름과 PID를 표시

(13) 하둡, 얀 클러스터 설정
1. 네임노드 초기화( nn1에서만 실행 )
hdfs namenode -format
2. NameNode 실행
hdfs --daemon start namenode
3. Standby NameNode 실행 ( nn2에서만 실행 )
hdfs namenode -bootstrapStandby
4. 하둡,얀 실행(nn1 에서만 실행)
start-dfs.sh >>> Hadoop 클러스터의 HDFS (Hadoop Distributed File System)를 시작하는 스크립트
start-yarn.sh >>> 리소스매니저 프로세스 실행, 나머지 datanode서버는 노드매니저 프로세스 실행됨
5. 잡히스토리 실행(nn1에서만 실행)
MapReduce JobHistoryServer는 Hadoop MapReduce 작업의 실행 이력 및 로그를 저장하고 관리하는 역할
mapred --daemon start historyserver >>> 잡히스토리서버 프로세스 실행
6. jps로 확인



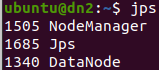

7. Active, Standby NameNode 확인
hdfs haadmin -getServiceState namenode1
hdfs haadmin -getServiceState namenode2

'데이터 엔지니어( 실습 정리 )' 카테고리의 다른 글
| 카프카 aws인프라(1) (0) | 2023.09.30 |
|---|---|
| 하둡, 스파크 코인 데이터 수집하기(2) (0) | 2023.08.11 |
| 하둡, 스파크 코인 데이터 수집하기(1) (0) | 2023.08.09 |
| (1일차-1)java, 하둡 설치 (0) | 2023.08.02 |
| (2일차-2) 웹 ui확인, 보안그룹 편집, 하둡 failover테스트 (0) | 2023.08.02 |

