데이터 엔지니어( 실습 정리 )/elasticsearch
4. 데이터 다루기 (1, 2)
세용용용용
2024. 12. 14. 18:21

[ 엘라스틱 서치 바이블 ] 공부한 후 정리한 내용 입니다!!!
1. 단건 문서 API
- 인덱스에 문서 ( 색인, 조회, 업데이트, 삭제 ) 하는 api
(1-1) 색인 api
### 색인 api ( 매서드 : put, post )
### _doc, _create 지정해 호출
curl -XPUT "http://192.168.219.20:9200/[인덱스명]/_doc/[_id 값]"
curl -XPOST "http://192.168.219.20:9200/[인덱스명]/_doc"
>>> _doc 대신 _create 사용 가능
>>> _create 사용시 항상 새 문서를 색인하는 경우만 허용 ( 덮어쓰기 금지 )
### _create 지정한 색인
curl -XPUT "http://192.168.219.20:9200/sy_index/_create/1?pretty" -H "Content-Type: application/json" -d \
'{
"title": "hello jiwon elasticsearch"
}'
- _create 지정한 색인은 덮어쓰기 금지!! ( already exists 이미 존재함 ㅋㅋ )
라우팅
- 라우팅 미 지정시 _id 해시값 기반 샤드가 배정
### 라우팅 지정 ( routing=[라우팅 명] )
curl -XPUT "http://192.168.219.20:9200/sy_index/_doc/2?routing=sy0218" -H "Content-Type: application/json" -d \
'{
"login_id": "sy0218",
"title": "jiwon love",
"created_ad": "2024-12-14"
}'
>>> 조회 : curl -XGET "http://192.168.219.20:9200/sy_index/_doc/2?pretty"
- 라우팅 지정시 _routing 필드에 라우티명 확인 가능
refresh
- 색인시 refresh 매개변수 지정하면 문서 색인 후 해당 샤드를 refresh 해서 즉시 검색 가능하게 만들 것인지 지정 가능

- 하지만 refresh 매개변수 지정시 고려 필요..
- 매번 refresh 호출시 클러스터 성능 저하..
- 너무 많은 작은 세그먼트 생성 ( 색인 이후 검색 성능 떨어짐, 추후 세그먼트 병합 과정도 부담이 커짐 )
- wait_for 기본값은 1000 ( 초당 1000건 이상 색인시 강제 refresh 수행 )
- 대량 색인 필요시 단건 색인이 아닌 bulk api 사용해야됨
(1-2) 조회 api
- 문서 단건 조회, refresh 되지 않은 상태서 변경된 내용 확인 가능
- 인덱스 명 + _id값 을 명시하고 호출
- 조회 api에서 라우팅 사용시 색인했을 떄 라우팅 명과 동일하게 지정 해줘야됨
### 조회 api
curl -XGET "http://192.168.219.20:9200/sy_index/_doc/2?pretty"
>>> _doc는 문서 메타데이터도 함께 조회
>>> _source는 문서 본문만 조회
필드 필터링
- 조회 api 사용시 ( _source_includes, _source_excludes ) 옵션 사용해 원하는 필드만 필터 가능
- 와일드 카드 사용 가능
### 필드 필터링 테스트
curl -XGET "http://192.168.219.20:9200/sy_index/_source/2?pretty&_source_includes=login_id,c*,t*&_source_excludes=created_ad"
>>> _source_incldes : 포함 필터
>>> _source_excludes : 제외 필터
(1-3) 업데이트 api
- 지정 문서 업데이트, 요청 본문에 ( doc, script ) 지정해 업데이트 내용 기술
- es 업데이트는 기존 문서 수정하는 것이 아님!!
- 문서 조회 내용 + 업데이트 내용 합쳐 새 문서를 색인하는 형태
- 즉, _source를 비활성화 시킨경우 업데이트 api 사용 불가!!
- 업데이트도 라우팅과 refresh 옵션 지정가능 ( 라우팅 색인 시와 동일, refresh는 성능 고려 )
### doc 업데이트
curl -XPOST "http://192.168.219.20:9200/sy_index/_update/2" -H "Content-Type: application/json" -d \
'{
"doc": {"login_id": "jiwon0725"}
}'
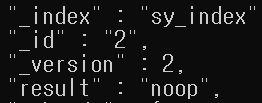
detect_noop
- es는 업데이터 작업 전 noop( 기존 변경이 없음 ) 인지 확인, noop이면 쓰기 작업 수행 안함
- noop 검사를 통해 불필요한 디스크 I/O 줄임
doc_as_upsert
- es 업데이트는 기존 문서가 없으면 요청이 실패
- 기존 문서 없을 경우 새로 문서를 추가하는 기능
### doc_as_upsert 테스트
curl -XPOST "http://192.168.219.20:9200/sy_index/_update/4?pretty" -H "Content-Type: application/json" -d \
'{
"doc": {"view": 27}, "doc_as_upsert": true
}'
script를 이용 업데이트
### script 업데이트
curl -XPOST "http://192.168.219.20:9200/sy_index/_update/4?pretty" -H "Content-Type: application/json" -d \
'{
"script": {
"source": "ctx._source.view += params.amount",
"lang": "painless",
"params": {"amount": 10}
},
"scripted_upsert": false
}'
>> script : 스크립트 사용 업데이트 시 script 필드안에 기술
>> source : 스크립트 본문이 기술
>> lang : 스크립트 언어 종류 지정
>> params : 스크립트 본문에 사용할 매개변수
>> scripted_upsert : 업데이트시 upsert 동작 여부 지정- 스크립트 사용 업데이트는 ctx 변수를 통해 문서 내용이나 메타데이터 접근 가능
(1-4) 삭제 api
- 문서를 삭제 ( DELETE 메서드 사용 )
- 삭제 api도 라우팅, refresh 지정 가능
### es 문서 삭제
curl -XDELETE "http://192.168.219.20:9200/sy_index/_doc/4?pretty"
2. 복수 문서 api
- 한건 단위로 http에 실어 나르는 것은 오버헤드가 큼..
- 서비스 환경에서 단건 문서 api 보단 복수 문서 api를 활용 ( 성능 차이 큼 )
(2-1) bulk API
- 여러 색인, 업데이트, 삭제 작업을 한번에 보내는 api
- 본문 요청 json이 아닌 ndjson 형태로 보냄 ( json >>> x-ndjson )
### bulk api 테스트
curl -XPOST "http://192.168.219.20:9200/_bulk?pretty" -H "Content-Type: application/x-ndjson" -d \
'
{"index": {"_index": "bulk_test", "_id": "1"}}
{"field1": "value1"}
{"delete": {"_index": "bulk_test", "_id": "2"}}
{"create": {"_index": "bulk_test", "_id": "3"}}
{"field1": "value3"}
{"update": {"_index": "bulk_test", "_id": "1"}}
{"doc": {"field2": "value2"}}
{"index": {"_index": "bulk_test", "_id": "4", "routing": "a"}}
{"field1": "value4"}
'
>>> 요청 종류, 인덱스, _id 라우팅 등을 기재
>>> 문서 내용이 필요한 요청의 경우 해당 내용 다음 줄에 적으면 됨
>>> 즉, 요청 하나의 크기는 ( 1줄 ~ 2줄 )
>>> api 요청시 ( [인덱스 명]/_bulk ) 인덱스 지정시 기본 인덱스로 지정됨
>>> index : 색인 작업 요청
>>> create : 색인 작업 요청 이지만 문서 존재시 작업 하지 않음
>>> update : 업데이트 요청
>>> delete : 삭제 요청
bulk API 작업 순서
- bulk api에 기술 순서로 작업된다는 보장은 없음
- 조정 노드는 요청을 보고 적절한 주 샤드로 요청을 넘기며, 각 요청은 독자적으로 수행 ( 즉, 순서 보장 안됨 )
- 하지만 동일 인덱스, _id, 라우팅 조합은 동일 샤드로 넘어가기에 기술된 순서로 동작
(2-2) multi get API
- 여러 문서를 한번에 조회하는 api
- 단건 조회 api 반복 사용하는 것보다 성능이 좋음
### multi get api 테스트
curl -XGET "http://192.168.219.20:9200/_mget?pretty" -H "Content-Type: application/json" -d \
'{
"docs": [
{"_index": "bulk_test", "_id": 1},
{"_index": "bulk_test", "_id": 4, "routing": "a"},
{"_index": "my_index2", "_id": 1, "_source": {"include": ["p*"], "exclude": ["point"]}}
]
}'
>>> [인덱스 명]/_mget 요청시 기본 인덱스 지정
### ids 만 기술해 요청 가능
curl -XGET "http://192.168.219.20:9200/bulk_test/_mget?pretty" -H "Content-Type: application/json" -d \
'{
"ids": [1, 4]
}'
(2-3) update by query
- 검색 쿼리를 통해 조건 만족하는 문서를 찾은뒤 해당 문서 대상으로 업데이트 실시하는 API
- script를 통한 업데이트만 지원
### update by query 테스트
curl -XPOST "http://192.168.219.20:9200/bulk_test/_update_by_query?pretty" -H "Content-Type: application/json" -d \
'{
"script": {
"source": "ctx._source.field1 = ctx._source.field1 + \"-\" + ctx._id", "lang": "painless"
},
"query": {
"exists": {"field": "field1"}
}
}'
>>> query 조건에 맞는 문서를 스냅샷으로 찍고
>>> 지정된 스크립트에 맞게 업데이트 실시
>>> 순차적 업데이트중 다른 작업으로 인해 문서가 변경될시 update by query는 찍어 두었던 스냅샷을 통해
변화가 생긴 문서를 확인하고 이를 업데이트 하지 않음!!!
>>> conflicts 매개변수를 통해 충돌 발견 시 작업 중단 및 다음 작업으로 넘어 갈수 있음 ( abort : 중단, proceed : 작업 넘어감 )
>>> update by query 작업중간 중단되더라고 이전까지 작업은 업데이트된 상태로 남음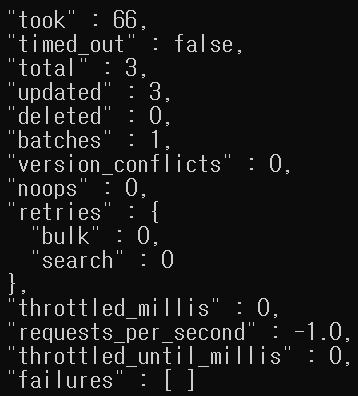
- 문서 갯수, 업데이트 수, 충돌, 재시도 등 필드를 확인 가능
- throttled_millis, requests_per_second, throttled_until_millis 필드는 스로틀링을 위한 필드
스로틀링
- update by query는 데이터를 일괄 수정 하는 작업에 많이 활용
- 대량 작업 수행시 운영 중 서비스에 영향을 줄수 있는데 이런 상황을 피하기 위해 스로틀링 기능 사용
### 스로틀링 테스트
!! 스로틀링을 적용해 작업의 속도를 조절하고 클러스터 부하 최소화 가능 !!
curl -XPOST "http://192.168.219.20:9200/bulk_test/_update_by_query \
?scroll_size=1000&scroll=1m&requests_per_seconds=500" -H "Content-Type: application/json" -d \
'{
~~~
}'
>>> scroll_size=1000
- 업데이트 전 검색을 수행해 문서 1000개를 가져오고 업데이트 수행
- 작업 단위 1000개 단위로 반복
>>> scorll=1m
- 검색 수행시 당시 상태를 검색 문맥에 보존 ( 스냅샷 찍는거 )
- 검색 문색을 얼마나 보존할지 지정
- 1m은 1분 동안 검색 문맥 유지
- scroll_size 작업 시간 만큼 시간을 지정하면됨
- 너무 크면 오버헤드 증가
>>> requests_per_second=500 ( -1은 스로틀링 적용 안함 )
- 스로틀링 실제 적용을 위해 설정 해줘야 하는 옵션
- 초 당 몇개 작업을 수행할 것 인지
- requests_per_second와 scroll_size 값을 조절하는 것이 스로틀링 조정 핵심!!- 실제 서비스 운영 중 대량의 update by query 작업시 스로틀링을 적용해 클러스터 부담과 서비스 리스크를 줄이며 안전하게 작업 수행
- 작업이 종료되는 시간이 오래 걸릴수 있어 tasks api를 사용해 update by query 비동기적 실행
- 비동기적 실행 : 작업을 es가 백그라운드로 실행하고 task id를 응답으로 받음
- task id를 통해 작업상태 추적 및 결과 확인 가능
비동기적 요청과 tasks api
- 엘라스틱서치 update by query 요청 시 wait_for_completion 매개변수 false로 지정시 비동기적 처리 가능
- 비동기 요청시 task id를 응답으로 받고 해당 id를 통해 tasks api를 호출함으로써 작업 진행이나 결과 및 취소 가능
### task 작업 등록과 상태 조회 테스트
curl -XPOST "http://192.168.219.20:9200/bulk_test/_update_by_query?pretty&wait_for_completion=false" -H "Content-Type: application/json" -d \
'{
"script": {
"source": "ctx._source.field1 = ctx._source.field1 + \"-\" + ctx._id", "lang": "painless"
},
"query": {
"exists": {"field": "field1"}
}
}'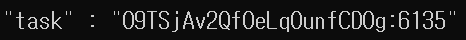
### task id를 가지고 task 상태 확인
curl -XGET "http://192.168.219.20:9200/.tasks/_doc/O9TSjAv2QfOeLqOunfCD0g:6135?pretty"
>>> 작업 상태 및 결과 확인 가능
>>> 비동기적 실행시 tasks api를 호출하여 작업을 관리
### task 작업 취소
curl -XPOST "http://192.168.219.20:9200/_tasks/O9TSjAv2QfOeLqOunfCD0g:6135/_cancel?pretty"
>>> 작업 진행 중 문제 발생시 작업을 취소
>>> task id를 알아낸 후 작업 취소 요청 가능
스로틀링 동적 변경
- 스로틀링 옵션을 동적 변경 가능 ( 유연한 대처를 위해 )
### 스로틀링 동적 변경 테스트
curl -XPOST "http://192.168.219.20:9200/_update_by_query/[task id]/_rethrottle?requests_per_second=[변경 값]"
>>> task id를 입력 후 스로틀링 변경값 기재
task 결과 삭제
- .tasks 인덱스에 등록된 작업이 성공, 취소 여부와 상관 없이 등록된 작업 결과는 es에 계속 남음
- 그렇기에 작업 상황이 충분이 이해 됬으면 .tasks 인덱스에 문서를 삭제
### task 결과 삭제
curl -XDELETE "http://192.168.219.20:9200/.tasks/_doc/O9TSjAv2QfOeLqOunfCD0g:582?pretty"
슬라이싱
- 업데이트 성능을 최대로 끌어내 빠른 시간 안에 끝내는 작업시 필요한 방법
- slices 매개변수로 업데이트를 지정한 개수로 쪼개 병렬적 수행
### 슬라이싱 테스트
!! 기본값은 1, auto는 엘라스틱서치가 적절한 개수를 지정해 작업을 병렬 수행 ( 보통 인덱스 주 샤드 수가 슬라이스 수 )
!! auto가 아닌 숫자도 지정 가능 !!
!! 슬라이스가 주 샤드 수보다 많을시 한 샤드 내에 데이터를 여러 슬라이스에 분배 해야되는데 해당 과정에서 오버헤드 발생 !!
curl -XPOST "http://192.168.219.20:9200/bulk_test/_update_by_query?pretty&slices=auto" -H "Content-Type: application/json" -d \
'{
"script": {
"source": "ctx._source.field1 = ctx._source.field1 + \"-\" + ctx._id", "lang": "painless"
},
"query": {
"exists": {"field": "field1"}
}
}'
(2-4) delete by query
- update by query와 동일하게 검색 쿼리로 삭제 대상 지정 뒤 삭제 수행
- update by query와 동일하게 스냅샷을 찍음
- conflicts, wait_for_completion, task api 관리, 스로틀링, 슬라이싱 관련 내용도 update by query와 동일
- 오래된 데이터, 더 이상 사용하지 않는 데이터를 삭제하는 경우에 많이 사용 ( 배치성 작업 많음 )
### delete by query
curl -XPOST "http://192.168.219.20:9200/bulk_test/_delete_by_query?pretty" -H "Content-Type: application/json" -d \
'{
"query": {
"wildcard": {
"field1": {"value": "*value*"}
}
}
}'
>>> field1 필드의 값에 value가 포함된 문서를 삭제하는 delete by query
- 총 3개의 문서가 삭제 된것을 확인