데이터 엔지니어( 실습 정리 )
hive 테이블 동적 Create, 실습 정리
세용용용용
2024. 7. 5. 21:23
0. hive : 대용량 데이터 관리를 위한 데이터 웨어하우스 인프라
- hdfs 위에 구축되어 있으며 HiveQL을 사용해 데이터를 쿼리하고 분석
주요 개념
1) 테이블
- 데이터가 저장됨, rdb와 유사하지만 hdfs 디렉터리와 파일로 구성
2) 데이터 베이스
- 테이블을 그룹화 하는 논리적 단위
3) 파티션
- 데이터를 더 세분화 관리하기 위해 파티션 사용
4) 버킷
- 파티션 내 데이터를 더 작게 나누기 위해 사용
5) 메타스토어
- 테이블 스키마와 메타데이터 정보를 저장하는 시스템
동작 원리
1) 쿼리작성 : HiveQL을 사용해 쿼리 작성
2) 쿼리 파싱 및 플래닝
- hive 쿼리 파싱해 실행계획 생성, 메타스토어 에서 테이블 및 스키마 정보 가져옴
3) MR 작업 생성
- hive 실행 계획을 mr 작업으로 변환, hadoop 클러스터에서 병렬로 처리
4) 작업 실행
- 변환된 mr작업이 hadoop 클러스터에서 처리
5) 결과 반환
- 처리 결과 반환
!!! RDB와 차이점 !!!
- RDB : 스키마를 정의하고 해당 틀에 맞게 데이터를 입력
- HIVE : 데이터를 저장후 해당 데이터에 맞는 스키마를 정의1. hive 테이블 CREATE ( 동적 으로 만들기 )
- hive 테이블 만드는 것도 어떻게 보면 반복 작업 이기에 동적으로 구현하기 위해 객체지향 프로그래밍 선택
- 꼭 제가 한게 정답은 아닙니당!! 저도 잘 모르고 새로운 것을 도전해보고 싶은 사람이라 ㅎㅎㅎ 참고만 해주세용!!!!
/data/db/hive/CREATE_hive_table.py
#!/usr/bin/python3
import sys
import subprocess
from datetime import datetime
class create_hive_table:
def __init__(self, database, table_name, columns, partitions, row_delimiter, field_delimiter, stored):
self.database = database
self.table_name = table_name
self.columns = columns
self.partitions = partitions
self.row_delimiter = row_delimiter
self.field_delimiter = field_delimiter
self.stored = stored
def log(self, message):
print(f"[{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}] Time_Stamp : {message}")
def drop_table(self):
drop_query = f"hive -e 'DROP TABLE IF EXISTS {self.database}.{self.table_name};'"
subprocess.run(drop_query, shell=True, check=True)
self.log(f"Dropped existing table: {self.database}.{self.table_name}")
def create_table_query(self):
columns_str = ", ".join([f"{col} STRING" for col in self.columns])
partitions_str = ", ".join([f"{part_name} {part_type}" for part_name, part_type in self.partitions.items()])
query = (
f"CREATE TABLE {self.database}.{self.table_name} (\n"
f" {columns_str}\n"
f")\n"
f"PARTITIONED BY (\n"
f" {partitions_str}\n"
f")\n"
f"ROW FORMAT DELIMITED\n"
f"FIELDS TERMINATED BY '{self.field_delimiter}'\n"
f"LINES TERMINATED BY '{self.row_delimiter}'\n"
f"STORED AS {self.stored}"
)
create_cmd = f"hive -e \"{query}\""
subprocess.run(create_cmd, shell=True, check=True)
self.log(f"CREATE table: {self.database}.{self.table_name}")
def run(self):
self.log("Create table Start....")
self.drop_table()
self.create_table_query()
self.log("Create table End....")
if __name__ == "__main__":
if len(sys.argv) != 8:
print("Usage: ./CREATE_hive_table.py database table_name columns partitions row_delimiter field_delimiter stored")
sys.exit(1)
database = sys.argv[1]
table_name = sys.argv[2]
columns = eval(sys.argv[3])
partitions = eval(sys.argv[4])
row_delimiter = sys.argv[5]
field_delimiter = sys.argv[6]
stored = sys.argv[7]
manager = create_hive_table(database, table_name, columns, partitions, row_delimiter, field_delimiter, stored)
manager.run()
실행 조건
# (실행파일) (hive 데이터베이스명) (hive 테이블명) (hive 컬럼) (hive 파티션) (행 구분자) (열 구분자) (Stored)
[실행파일] default test_table "['soldDate','itemName','count','unitPrice']" "{'pdate':'STRING'}" "\n" "\t" TextFile
hive 테이블 생성 확인 명령어
show create table [테이블명]
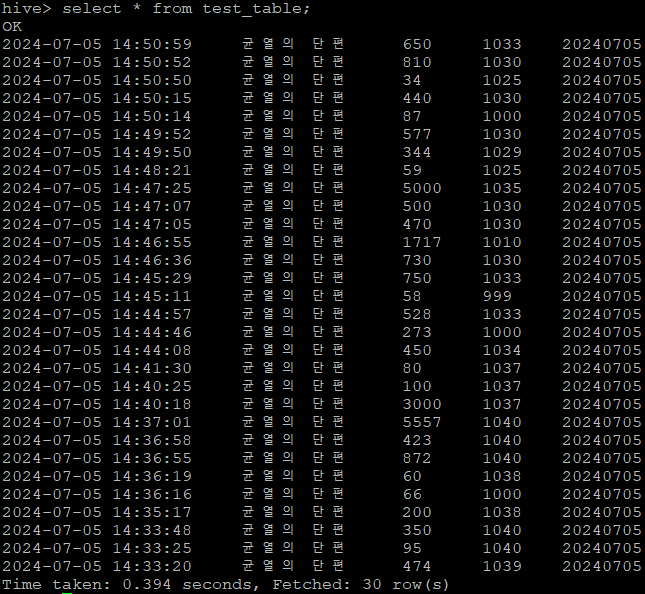
2. test 데이터 넣기
/data/scripts/get_sh/test.py : 던파 api 데이터 가져오는 실행파일
#!/usr/bin/python3
import requests
import csv
from datetime import datetime
def row_data(dict_values):
answer = []
for key in ['soldDate','itemName','count','unitPrice']:
answer.append(str(dict_values[key]))
return '\t'.join(answer)
# API 엔드포인트 URL
api_url = "https://api.neople.co.kr/df/auction-sold"
# 파라미터 설정
params = {
"itemName": "균열의 단편",
"wordType": "match",
"wordShort": "false",
"limit": 30,
"apikey": "JUG54ELPbKttanbis2VPFNqC9LJOM7v4"
}
# GET 요청 보내기
response = requests.get(api_url, params=params)
data = response.json()
test1 = data.get("rows")
for dict_values in test1:
print(row_data(dict_values))
/data/scripts/get_sh/test_get.sh : 가져온 row데이터 로컬에 txt파일로 리다이렉트 하는 스크립트
#!/bin/bash
# 인자 개수 확인
if [ "$#" -ne 1 ]; then
echo "Usage: $0 YYYYmmdd"
exit 1
fi
# 현재 날짜 구하기
mydate=$1
# 파이썬 스크립트 실행하여 결과를 파일에 저장
python3 /data/scripts/get_sh/test.py > /data/row_data/"${mydate}"_test.txt
/data/scripts/test/test_2hive : 로컬 txt파일 hive에 넣는 스크립트(웨어하우징)
#!/bin/sh
if [ $# -ne 1 ] || [ `echo $1 | wc -c` -ne 9 ]; then
echo "$0 YYYYMMDD"
exit
fi
GDATE=$1
DATA_DIR="/data/row_data"
DATA_FILE="${GDATE}_test.txt"
hive_table_name="test_table"
hadoop_dir="/data/test/"
hadoop_file="test_${GDATE}"
# 디렉토리 존재하지 않으면 생성
hdfs dfs -test -e ${hadoop_dir} || hdfs dfs -mkdir -p ${hadoop_dir}
# 파일 존재시 삭제(멱등성 위해)
hdfs dfs -test -e ${hadoop_dir}/${hadoop_file} && hdfs dfs -rm ${hadoop_dir}/${hadoop_file}
# 로컬파일 hdfs에 put
hdfs dfs -put ${DATA_DIR}/${DATA_FILE} ${hadoop_dir}/${hadoop_file}
# hive에 넣기
hive -e "set mapred.job.priority=VERY_HIGH;load data inpath '${hadoop_dir}/${hadoop_file}' overwrite into table ${hive_table_name} partition (pdate='${GDATE}')"
hive 테이블 확인하는 명령어(hiveQL)
select * from [테이블명]