0. 기준시간 변경
우분투에서 시간을 먼저 변경해준다( 데이터 수집 시간 데이터를 수집하기 위해)
1. 현재 시간과 날짜 표시
timedatectl >>> 역시나 서울로 안되있음 서울로 바꿔줘야됨

2. sudo timedatectl set-timezone "Asia/Seoul" >>> 서울로 바꿔주자
3. 변경후 timedatectl로 바뀌었는지 확인해주며됨
1. 토픽 생성
저장 아이템 : 무결점 라이언 코어
$KAFKA_HOME/bin/kafka-topics.sh --create \
--bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092 \
--replication-factor 2 \
--partitions 3 \
--topic donpa2 \
--config retention.ms=1800
저장 아이템 : 무결점 골든 베릴
$KAFKA_HOME/bin/kafka-topics.sh --create \
--bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092 \
--replication-factor 2 \
--partitions 3 \
--topic donpa3 \
--config retention.ms=1800
저장 아이템 : 무색 큐브 조각
$KAFKA_HOME/bin/kafka-topics.sh --create \
--bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092 \
--replication-factor 2 \
--partitions 3 \
--topic donpa4 \
--config retention.ms=1800
토픽 생성되었는지 확인
$KAFKA_HOME/bin/kafka-topics.sh --bootstrap-server kafka01:9092,kafka02:9092,kafka03:9092 \
--list
2. 토픽에 데이터 저장
vi donpa_test2.py
from confluent_kafka import Producer
import requests
import json
import time
import pandas as pd # pandas 라이브러리 임포트
# 이전 데이터를 추적하기 위한 변수 초기화
last_data = None
# Kafka 설정
kafka_config = {
'bootstrap.servers': 'kafka01:9092,kafka02:9092,kafka03:9092',
'client.id': 'api-producer'
}
# Kafka 프로듀서 생성
producer = Producer(kafka_config)
# API 엔드포인트 및 파라미터 설정
api_url = "https://api.neople.co.kr/df/auction-sold"
params = {
"itemName": "무결점 라이언 코어",
"wordType": "match",
"wordShort": "false",
"limit": 1,
"apikey": "Q3A8yWb7Un1oXuM7uC5nIRV6zzGL23YP"
}
# 주기적으로 API 호출 및 데이터를 Kafka 토픽에 전송
while True:
try:
response = requests.get(api_url, params=params)
data = response.json()
data = data.get('rows')
data = [{"soldDate": row["soldDate"], "itemName": row["itemName"], "count": row["count"], "unitPrice": row["unitPrice"]} for row in data]
data = data[0]
# 이전 데이터와 중복되지 않는 경우에만 데이터를 전송
if data != last_data:
last_data = data
message = json.dumps(data, ensure_ascii=False).encode('utf-8')
# Kafka 토픽에 데이터 전송
producer.produce("donpa2", key="api_data", value=message)
# 전송한 메시지 확인
producer.poll(0)
print("API 데이터를 Kafka 토픽에 전송했습니다.")
except Exception as e:
print(f"오류 발생: {str(e)}")
# 5분(300초) 대기
time.sleep(10)백드라운드 실행 >>> python3 donpa_test2.py &
백그라운드 실행 중지 >>> ps aux | grep donpa_test2.py
kill해주기
2) 토픽에 들어갔는지 확인(kafka02)
$KAFKA_HOME/bin/kafka-console-consumer.sh --bootstrap-server kafka01:9092,kafka:9092,kafka:9092 --topic donpa2 --from-beginning

나머지 아이템도 똑같이 데이터 수집해주자


3) 토픽에 데이터가 들어갈때마다 스파크 스트리밍을 통해 hdfs데이터 저장
vim donpa_item2.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType, TimestampType
sc = SparkSession.builder \
.master('yarn') \
.appName('donpa_spark_stream') \
.config("spark.yarn.am.memory", "200m") \
.config("spark.yarn.am.cores", "1") \
.getOrCreate()
sc.sparkContext.setLogLevel('INFO')
# read stream
df = sc.readStream.format('kafka') \
.option("kafka.bootstrap.servers", "kafka01:9092,kafka02:9091,kafka03:9092") \
.option("subscribe", "donpa2") \
.option("startingOffsets", "earliest") \
.load()
# JSON 스키마 정의
schema = StructType([
StructField("soldDate", TimestampType(), True),
StructField("itemName", StringType(), True),
StructField("count", IntegerType(), True),
StructField("unitPrice", DoubleType(), True)
])
# value 컬럼을 JSON 파싱
df = df.selectExpr("CAST(value AS STRING) as json")
df = df.select(from_json(df.json, schema).alias("data"))
# Define a function to process each batch
def process_batch(batch_df, batch_id):
if batch_id == 0:
# Skip processing for batch ID 0
pass
else:
# Your processing logic for other batch IDs
batch_df.write.option("header", "true") \
.format("csv") \
.mode("append") \
.save("/donpa2_spark_stream")
# Write stream - HDFS using foreachBatch
query2 = df.select("data.*").writeStream \
.foreachBatch(process_batch) \
.outputMode("append") \
.start()
query2.awaitTermination()# YARN 큐 자원 제한 설정( 디폴트 요청은 메모리 1024m, 가상코어 1)
# 큐 이름 지정
sc.conf.set("spark.yarn.queue","donpa4_queue")
# 메모리 제한 설정
sc.conf.set("spark.executor.memory", "300m")
# 가상 코어 제한 설정
sc.conf.set("spark.executor.cores", "1")
러닝 컨테이너 수 제한
spark-submit --num-executors 2 --executor-cores 1
nohup spark-submit --master yarn --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.0 /home/ubuntu/dataflow_topic_hdfs/donpa_item1.py > /dev/null 2>&1 &
>>> 표준출력 무시, 백그라운드 실행 명령어
나머지 아이템도 똑같이 수집해주자

수집 되는것을 확인!!
4) 최근 30분의 거래 데이터를 데이터 프레임을 데이터 마트인 RDB에 넣어보자
마리아DB 설치할 인스턴스 생성해주자
# 시스템 패키지 정보를 업데이트
sudo apt update
# 마리아 db설치
sudo apt install mariadb-server
# MariaDB 서버를 시작합니다
sudo systemctl start mariadb
# 부팅 시 자동으로 시작하도록 MariaDB를 활성화
sudo systemctl enable mariadb
# MariaDB에 root 사용자로 로그인
sudo mysql -u root
# root 사용자의 비밀번호를 설정
alter user 'root'@'localhost' identified by '1234';
# 권한을 새로 고침
FLUSH PRIVILEGES;
# MariaDB에서 데이터베이스를 생성
CREATE DATABASE donpa_datamart1;
# 해당 데이터베이스 사용
use donpa_datamart1
# 데이터베이스를 삭제
DROP DATABASE donpa_datamart1;
마리아DB에서 모든 통신을 허용
sudo vim /etc/mysql/mariadb.conf.d/50-server.cnf

0.0.0.0 으로 변경
마리아DB 서비스를 재시작하여 변경 사항을 적용 >>> sudo systemctl restart mariadb
마리아DB 3306포트에서 실행중인지 확인 >>> sudo ss -tuln | grep 3306

nn1에서 접속 테스트 해보기
sudo apt install mariadb-client-core-10.3 >>> 마리아db 클라이언트 설치
# 마리아db에서
mysql -u root -p >> 접속후
SELECT host, user FROM mysql.user; >> 호스트 접근권한 확인
# 172.31.41.230 접근권한 설정
GRANT ALL PRIVILEGES ON *.* TO 'root'@'172.31.41.230' IDENTIFIED BY '1234' WITH GRANT OPTION
# 편의상 모든 ip 접근권한 설정
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '1234' WITH GRANT OPTION;
FLUSH PRIVILEGES; >>> 변경사항 적용
# nn1에서 접속해보기
mysql -h 172.31.41.158 -u root -p
성공
이제 최근 30분 거래데이터 마리아db에 넣어보자
1) mariadb-java-client 설치
mkdir mariadb_jdbc
sudo apt-get install wget
wget https://downloads.mariadb.com/Connectors/java/connector-java-2.7.0/mariadb-java-client-2.7.0.jar
2) 스파크 jars에 복사
sudo cp /home/ubuntu/mariadb_jdbc/mariadb-java-client-2.7.0.jar /usr/local/spark/jars/ >>> 복사
ls /usr/local/spark/jars/mariadb-java-client-2.7.0.jar >>> 잘 복사되었는지 확인

3) 최근 30분 거래데이터 마리아db에 넣는 코드
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType, TimestampType
spark = SparkSession.builder \
.master('yarn') \
.appName('show_df') \
.getOrCreate()
# MaríaDB 연결 정보 설정
mariadb_url = "jdbc:mysql://172.31.41.158:3306/donpa_datamart1"
mariadb_properties = {
"user": "root",
"password": "1234",
"driver": "org.mariadb.jdbc.Driver"
}
import subprocess
import datetime
# 현재 시간과 30분 뺀 시간 계산
current_time = datetime.datetime.now()
time_threshold = current_time - datetime.timedelta(minutes=30)
# HDFS 디렉토리 경로
hdfs_directory = "/donpa1_spark_stream"
# HDFS 디렉토리 내 파일 목록 가져오기
hdfs_ls_command = f"hdfs dfs -ls {hdfs_directory}"
result = subprocess.run(hdfs_ls_command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
# 가져온 파일 목록을 줄 단위로 분할
file_lines = result.stdout.strip().split('\n')
# 파일 목록을 시간 역순으로 정렬
sorted_files = sorted(file_lines, key=lambda line: line.split()[-2], reverse=True)[1:]
# 스키마 정의
schema = StructType([
StructField("soldDate", TimestampType(), True),
StructField("itemName", StringType(), True),
StructField("count", IntegerType(), True),
StructField("unitPrice", DoubleType(), True)
])
# 빈 데이터 프레임 생성
result_df = spark.createDataFrame([], schema)
index_num = 2
hdfs_path_list = []
while index_num < len(sorted_files):
# 파일 가져오기
file = sorted_files[index_num]
# 파일 생성시간 추출
file_time_str = file.split()[-3] + ' ' + file.split()[-2]
file_time = datetime.datetime.strptime(file_time_str, '%Y-%m-%d %H:%M')
if file_time >= time_threshold:
# 파일 경로 파싱
file_path = file.split()[-1]
hdfs_path_list.append(file_path)
# index_num 증감
index_num += 1
else:
break
for i in hdfs_path_list:
df = spark.read.option('header', 'true').csv(f'hdfs://{i}')
result_df = df.union(result_df)
# DataFrame을 사용하여 원하는 작업을 수행할 수 있습니다.
result_df.show()
# MaríaDB에 데이터프레임 쓰기
result_df.write \
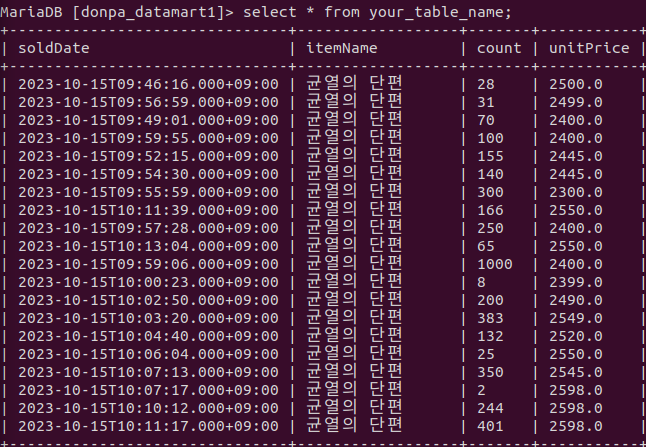
.jdbc(url=mariadb_url, table="your_table_name", mode="overwrite", properties=mariadb_properties)
# 스파크 애플리케이션 종료
spark.stop()spark-submit --master yarn --deploy-mode client --jars /usr/local/spark/jars/mariadb-java-client-2.7.0.jar donpa_item1.py >>> 스파크 애플리케이션 실행 해보자
데이터 마트에 저장되었는지 확인!!

5) 최근 30분의 거래 데이터로 데이터 마트를 최신화 시키는 워크플로우로 정의해보자(airflow사용)
- 아파치 에어플로우는 워크플로우 자동화 및 스케줄링 도구
sudo apt install python3-venv # Python 가상 환경을 만들기 위한 기본 패키지
python3 -m venv airflow-env # 새 가상 환경 생성
source airflow-env/bin/activate # 새 가상 환경 활성화
1. airflow를 설치후 실행, 이후 웹ui에 접속해 작업을 정의
(1) pip install apache-airflow >>> airflow 설치
버전 호환 맞춰주기
pip install werkzeug==2.2.2
pip install cachelib==0.9.0
(2) echo 'export PATH="$PATH:$HOME/.local/bin"' >> ~/.bashrc : airflow 명령이 설치된 경로가 PATH 환경 변수에 추가,
추가하지 않으면 나중에 airflow 명령을 사용할때 경로를 입력해야하는 불편함 초래...
source ~/.bashrc >> 변경사항 적용
(3) airflow db init : airflow 초기화
(4) cd airflow >>> vim airflow.cfg

9898포트로 변경해주자
timezone두 서울로 바꿔주자

false로 수정
rm -rf ./airflow.db
airflow db init
(5) airflow users create --username wntpdyd0218 --firstname syoung --lastname ju --role Admin --email sy02229@gmail.com --password 1234
사용자 이름 : wntpdyd0218
비밀번호 : 1234
(6) airflow webserver -D >>> 에어플로우 웹서버 백그라운드 실행후
http://외부ip:9898 접속
2. DAG 정의 파일을 작성
(1) vi airflow.cfg

dag디렉토리명 위치 확인후 해당위치에
mkdir dags >>> dags 디렉토리 생성해주기
cd dags >>> 해당 위치에서 파일 작성!!
donpa_item01.py
from airflow.operators.bash_operator import BashOperator
from airflow import DAG
from datetime import datetime, timedelta
import pytz
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 10, 15),
'retries': 1,
'retry_delay': timedelta(minutes=5),
'timezone': 'Asia/seoul',
}
dag = DAG(
'donpa_itme01_dag',
default_args=default_args,
schedule_interval='*/30 * * * *', # 30분마다 실행
catchup=False, # 과거 작업은 실행하지 않음
)
# 실행
mariadb_submit_task = BashOperator(
task_id='mariadb_update',
bash_command='/usr/local/spark/bin/spark-submit --master yarn --deploy-mode client --jars /usr/local/spark/jars/mariadb-java-client-2.7.0.jar /home/ubuntu/dataflow_hdfs_datamart/donpa_item1.py',
dag=dag,
)
# Task 간 의존성 설정
# mariadb_submit_task >> mariadb_submin_tast1airflow scheduler -D : scheduler 백그라운드 실행하기
airflow 웹사이트에 들어가보면(실행시켜주자)

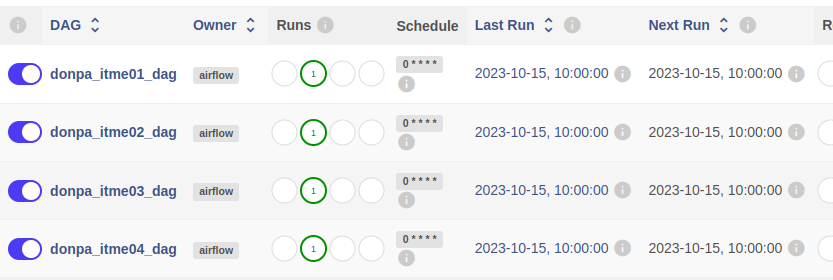
데이터 마트 확인시 최근 30분 거래데이터로 최신화 된것을 확인!!
다른 아이템들도 위와 똑같이 데이터 마트를 생성하고 워크플로우를 정의해보자

6) 데이터 마트에 들어간 1시간 동안 거래 데이터를 실시간 bi툴로 시각화 해보자
Redash를 사용해 던파 데이터를 시각화 대시보드로 구현해보자!!
ec2 인스턴스 하나만들어주자 우분투20.04, t2미디움으로
1) 먼저 도커를 설치해주자
# 패키지 업데이트를 수행
sudo apt-get update
# Docker 패키지 관련 소프트웨어 및 의존성 패키지를 설치
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
# Docker 공식 GPG 키를 추가
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# Docker 저장소를 시스템에 추가
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
# Docker CE를 설치
sudo apt-get install -y docker-ce
# Docker 서비스를 시작
sudo systemctl start docker
sudo systemctl enable docker
# 현재 사용자를 Docker 그룹에 추가하여 루트 권한 없이 Docker를 사용할 수 있도록함
sudo usermod -aG docker $USER
2) Redash 설치 및 실행
#패키지 업데이트
sudo apt update
#git 설치
sudo apt install git
#redash setup clone
git clone https://github.com/getredash/setup.git
cd setup/
#setup 스크립트 실행 권한
sudo chmod +x setup.sh
#스크립트 실행
./setup.sh
docker ps -a >>> 시스템에 있는 모든 Docker 컨테이너를 나열

http://외부ip:5000 >>> redash접속

로그인 화면

3) Redash 기본 개념
오픈 소스 비즈니스 인텔리전스 도구로, 데이터 시각화 및 대시보드 작성, 데이터 쿼리 및 다양한 데이터 소스와의 통합을 지원
Redash를 사용하여 데이터를 시각화하고 실시간 대시보드를 만들 수 있음
1. 대시보드 : 작성한 쿼리를 테이블, 차트 형태로 등록하여 종합적인 시각화를 구현
2. 데이터소스 : 대시보드에 시각화할 데이터의 저장소(기본적으로 db등이 있음)
3. 쿼리 : db와 똑같이 쿼리라고 생각하면됨 데이터에서 필요한 값을 뽑아내는 최종 결과값을 테이블, 차트 형태로 표현
4. Alert(알림) : 생성한 쿼리의 값에 조건을 걸어 만족하면 알림을 보내준다. 트리거 느낌????
4) Redash db연결
1. 우측 상단 가운데 모양 클릭

2. + New Data Source클릭
3. mysql 선택
4. 데이터 소스 등록

등록후 data sources목록을 보면 등록완료
이제 db연결을 완료했으니 시각화할 쿼리를 만들어 보자
5) Create Query
create >>> query클릭
1. 쿼리 실행 및 등록
해당 창에서 왼쪽은 데이터 소스를 선택할수는 창과 맨위의 new query는 쿼리의 이름이다.클릭해서 변경가능오른쪽은 쿼리를 작성하고 execute버튼으로 퀴리가 실행됨 마지막으로 save는 저장하는것
테스트로 테이블의 모든 데이터를 출력해보자(시간순으로 정렬) >>> SELECT * FROM donpa_item01
ORDER BY soldDate;

+ New VisualiZation 클릭하여 차트를 만들어주자
최근 가격 변동을 시각화

SAVE를 누르면 하단 테이블 옆에 추가된다

쿼리와 chart 작업후 내용 저장을 위해 save를 해준다
최종적으로 생성쿼리를 대시보드에 등록하기 위해 Publish버튼을 클릭

2. 작성한 쿼리를 대시보드에 등록해 모니터링 해보자
create >>> Dashboard 클릭

대시보드 이름 작성후 save
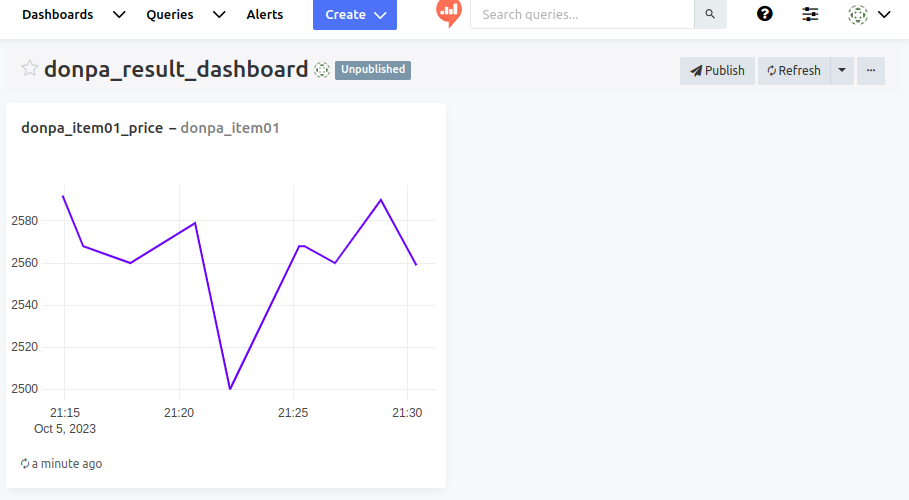
아래는 대시보드 화면이다. 쿼리 등록을 위해 add widget버튼 클릭

쿼리선택후 원하는 visualization선택하자

선택후 add to Dashboard 클릭

대시보드에 차트가 삽입된것을 확인

대시보드 변경사항 적용을 위해 상단의 Done Editing클릭

최종적으로 상단의 Publish를 클릭해 대시보드를 Publish시킴
총 거래 건수를 확인하는 쿼리 하나를 더 추가해보자
쿼리 등록 ( 이미지를 추가하기위해 빈 컬럼 추가)
SELECT '' AS image, itemName, SUM(count) AS total_count FROM donpa_item01 GROUP BY itemName;
visualization Type를 테이블로하고 image컬럼을 이미지 링크를 달아준다

작성후 쿼리를 저장해주자
이제 기존 대시보드에 쿼리를 추가하기위해 edit클릭

추가후 대시보드 저장

다른 아이템도 동일하게 쿼리 구현후 대시보드 완성해주자
8) 던파 아바타 데이터를 hdfs에 저장해보자
아바타는 거래횟수가 크지 않으므로 실시간 스트림 보다는 배치처리를 활용해 데이터를 수집해보자
vi rare_aabata.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import DoubleType
import requests
# 스파크 세션 생성
spark = SparkSession.builder \
.master("yarn") \
.appName("aabataProcessing") \
.getOrCreate()
# API 엔드포인트 URL
api_url = "https://api.neople.co.kr/df/avatar-market/sold"
# 파라미터 설정
params = {
"limit": 50,
"q": 'avatarSet:true,avatarRarity:레어',
"apikey": "Q3A8yWb7Un1oXuM7uC5nIRV6zzGL23YP"
}
# GET 요청 보내기
response = requests.get(api_url, params=params)
# 응답 데이터 확인
if response.status_code == 200:
data = response.json()
# 데이터 처리 및 출력
#print(data)
else:
print("API 요청 실패:", response.status_code)
test1 = data.get("rows")
# 필요한 필드만 추출하여 저장할 리스트
extracted_data = []
for item in test1:
title = item['title']
jobname = item['jobName']
price = item['price']
ava_rit = item['avatarRarity']
emblem = item['emblem']['name']
soldDate = item['soldDate']
extracted_data.append({'title': title, 'price': price, 'ava_rit': ava_rit, 'jobname': jobname,
'emblem': emblem, 'soldDate': soldDate})
# 데이터 프레임 생성
df = spark.createDataFrame(extracted_data)
# 원하는 순서로 컬럼 선택
df = df.select('soldDate', 'title', 'ava_rit', 'jobname', 'emblem', 'price')
# 중복 레코드 제거
df = df.dropDuplicates()
# soldDate 컬럼을 기준으로 정렬
df = df.orderBy("soldDate")
# csv파일로 저장
csv_path = "donpa_aabata_rare.csv"
df.write.csv(csv_path, header=True, mode="overwrite")
# 스파크 세션 종료
spark.stop()spark-submit --master yarn --deploy-mode client rare_aabata.py
저장 확인

이제 레어 아바타 거래 데이터를 수집해 기존의 csv와 합쳐서 다시 저장하는 코드 작성
vi marge_rare_aabata.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import DoubleType
import requests
import os
# 스파크 세션 생성
spark = SparkSession.builder \
.master("yarn") \
.appName("aabataProcessing") \
.getOrCreate()
# API 엔드포인트 URL
api_url = "https://api.neople.co.kr/df/avatar-market/sold"
# 파라미터 설정
params = {
"limit": 50,
"q": 'avatarSet:true,avatarRarity:레어',
"apikey": "Q3A8yWb7Un1oXuM7uC5nIRV6zzGL23YP"
}
# GET 요청 보내기
response = requests.get(api_url, params=params)
# 응답 데이터 확인
if response.status_code == 200:
data = response.json()
# 데이터 처리 및 출력
#print(data)
else:
print("API 요청 실패:", response.status_code)
test1 = data.get("rows")
# 필요한 필드만 추출하여 저장할 리스트
extracted_data = []
for item in test1:
title = item['title']
jobname = item['jobName']
price = item['price']
ava_rit = item['avatarRarity']
emblem = item['emblem']['name']
soldDate = item['soldDate']
extracted_data.append({'title': title, 'price': price, 'ava_rit': ava_rit, 'jobname': jobname,
'emblem': emblem, 'soldDate': soldDate})
# 데이터 프레임 생성
df = spark.createDataFrame(extracted_data)
# 원하는 순서로 컬럼 선택
df = df.select('soldDate', 'title', 'ava_rit', 'jobname', 'emblem', 'price')
# 중복 레코드 제거
df = df.dropDuplicates()
# soldDate 컬럼을 기준으로 정렬
df = df.orderBy("soldDate")
try:
previous_df = spark.read.option("header", "true").csv("hdfs:///user/ubuntu/donpa_aabata_rare.csv/*.csv")
except:
previous_df = None
if previous_df is not None:
merged_df = previous_df.union(df)
# 중복 레코드 제거
merged_df = merged_df.dropDuplicates()
# soldDate 컬럼을 기준으로 정렬
merged_df = merged_df.orderBy("soldDate")
# csv파일로 저장
merged_df.write.csv("new_donpa_aabata_rare.csv", header=True, mode="overwrite")
# 기존 디렉토리 삭제
os.system("hdfs dfs -rm -r donpa_aabata_rare.csv")
# 새로운 디렉터리 이름 변경
os.system("hdfs dfs -mv new_donpa_aabata_rare.csv donpa_aabata_rare.csv")
else:
# 바로저장
df.write.csv("donpa_aabata_rare.csv", header=True, mode="overwrite")
print("성공")
# 스파크 세션 종료
spark.stop()spark-submit --master yarn --deploy-mode client marge_rare_aabata.py
9) 던파 아바타 데이터를 마리아db에 저장
vi rare_aabata_save_rdb.py
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType, TimestampType
spark = SparkSession.builder \
.master('yarn') \
.appName('daflow_aabata_hdfs_rdb') \
.getOrCreate()
# MaríaDB 연결 정보 설정
mariadb_url = "jdbc:mysql://172.31.41.158:3306/donpa_datamart1"
mariadb_properties = {
"user": "root",
"password": "1234",
"driver": "org.mariadb.jdbc.Driver"
}
# HDFS에서 CSV 파일 읽어오기
csv_path = "hdfs:///user/ubuntu/donpa_aabata_rare.csv/*.csv"
csv_df = spark.read.option("header", "true").csv(csv_path)
csv_df.show()
# MaríaDB에 데이터프레임 쓰기
csv_df.write \
.jdbc(url=mariadb_url, table="rare_aabata", mode="overwrite", properties=mariadb_properties)
# 스파크 애플리케이션 종료
spark.stop()실행
spark-submit --master yarn --deploy-mode client --jars /usr/local/spark/jars/mariadb-java-client-2.7.0.jar rare_aabata_save_rdb.py
저장되었는지 확인

상급 아바타도 위와 같은 방식으로 저장해주자
10) 던파 아바타 거래 데이터 1시간 마다 데이터 마트 최신화 시켜주는 워크플로우 airflow활용해 정의해주자
1시간 마다 거래 데이터 수집해 hdfs에 저장 >>> hdfs데이터 데이터마트(rdb)에 저장
dags에 파일 정의
vi donpa_aabata_rare.py
from airflow.operators.bash_operator import BashOperator
from airflow import DAG
from datetime import datetime, timedelta
import pytz
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 10, 15),
'retries': 1,
'retry_delay': timedelta(minutes=5),
'timezone': 'Asia/seoul',
}
dag = DAG(
'spark_aabata_rare_dag',
default_args=default_args,
schedule_interval='30 * * * *', # 정각 마다 실행
catchup=False, # 과거 작업은 실행하지 않음
)
# hdfs에 데이터 저장
spark_submit_task = BashOperator(
task_id='aabata_rare_load_csv',
bash_command='/usr/local/spark/bin/spark-submit --master yarn --deploy-mode client /home/ubuntu/dataflow_aabata_hdfs/marge_rare_aabata.py',
dag=dag,
)
# mariadb에 데이터 저장
push_maria_task = BashOperator(
task_id='aabata_rare_push_mariadb',
bash_command='/usr/local/spark/bin/spark-submit --master yarn --deploy-mode client --jars /usr/local/spark/jars/mariadb-java-client-2.7.0.jar /home/ubuntu/dataflow_aabata_hdfs_datamart/rare_aabata_save_rdb.py',
dag=dag,
)
# Task 간 의존성 설정
spark_submit_task >> push_maria_task
상급 아바타도 동일한 워크플로우 작성해주자
최종 airflow

11) 최종적으로 실시간 bi툴로 시각화 해보자(Redash)
아바타 쿼리(내림 차순으로 정렬)
SELECT * FROM rare_aabata
ORDER BY soldDate DESC;
아바타명 use for search옵션을 사용해 검색 옵션을 달아준다

상급아바타도 동일한 쿼리 작성후 대시보드에 등록해주자
12) 최종대시보드
던파 아이템은 정각마다 최신화 되어 1시간 동안 거래 정보를 시각화던파 아바타는 30분마다 최신화 되어 추가된 거래정보를 마트에 적용하여 거래정보를 테이블을 통해 확인( 아바타 명 검색옵션 추가)

왼쪽 상단 공유 이미지 클릭하여 대시보드 배포

nn1에서 crontab -e
매주 월요일마다 로그 지워주기
0 0 * * 1 sudo find /usr/local/spark/logs/ -type f -delete
dn1, dn2, dn3,dn4,dn5,dn6 crontab -e
30분마다 캐시 지워주기
*/30 * * * * rm -rf /tmp/hadoop-ubuntu/nm-local-dir/usercache/ubuntu/filecache/*
'데이터 엔지니어( 실습 정리 )' 카테고리의 다른 글
| hive실습 (0) | 2023.11.23 |
|---|---|
| hive 웨어하우징 실습(쉘 스크립트), airflow (0) | 2023.11.22 |
| 카프카, 스파크 스트리밍,하둡 던파 실시간 대시보드 총정리 (2) | 2023.10.06 |
| 데이터마트 데이터 bi툴로 실시간 대시보드 구현(3) (1) | 2023.10.06 |
| hdfs던파 아이템 데이터 데이터 마트에 저장(1) (0) | 2023.10.06 |

